Advice and Tips
This section does not contain any design requirements (i.e. you could complete the whole project without reading this section). However, we’ve compiled some advice about how to approach the project in this section.
Testing with Ginkgo
This section provides some basic documentation for Ginkgo, which is the framework you’ll be using to write your own test cases.
First, we recommend reading through the basic tests in client_test.go, especially the first few ones, since those are well-documented in-line. Then, come back to this documentation.
Basic Usage
You should be able to write most of your tests using some combination of calls to –
- Initialization methods (e.g.
client.InitUser,client.GetUser) - User-specific methods (e.g.
alice.StoreFile,bob.LoadFile) - Declarations of expected behavior (e.g.
Expect(err).To(BeNil()))
Asserting Expected Behavior
To assert expected behavior, you may want to check (a) that an error did or didn’t occur, and/or (b) that some data was what you expected it to be. For example:
// Check that an error didn't occur
alice, err := client.InitUser("alice", "password")
Expect(err).To(BeNil())
// Check that an error didn't occur
err = alice.StoreFile("alice.txt", []byte("hello world"))
Expect(err).To(BeNil())
// Check that an error didn't occur AND that the data is what we expect
data, err := alice.LoadFile("alice.txt")
Expect(err).To(BeNil())
Expect(data).To(Equal([]byte("hello world")))
// Check that an error DID occur
data, err := alice.LoadFile("rubbish.txt")
Expect(err).ToNot(BeNil())
Organizing Tests
You can organize tests using some combination of Describe(...) containers, with tests contained within Specify(...) blocks. The more organization you have, the better! Read more about how to organize your tests here.
Optional: Measure Local Test Coverage
To measure and visualize local test coverage (e.g. how many lines of your implementation your test file hits), you can run these commands in the root folder of your repository:
go test -v -coverpkg ./... ./... -coverprofile cover.out
go tool cover -html=cover.out
Coverage over your own implementation may serve as an indicator for how well your code will perform (with regards to coverage flags) when compared to the staff implementation! It should also help you write better unit testing to catch edge cases.
Tips on Database Architecture
Whenever you’re thinking about storing lists or maps of things in Datastore, it may help to think about how you can “flatten” your data structure - this might help with security, efficiency, and/or code complexity! As an example: let’s say we have a list of restaurants, where each restaurant has a list of menu items. Let’s say I want to figure out whether a particular restaurant has a specific menu item, and we’re using a datastore-like backend (a key-value store).
Consider these two approaches to representing this information in some key-value store:
// Approach A</span>
{
"movies": {
"mcu": ["iron man", "the incredible hulk", "iron man 2", "thor", "captain america", "the avengers"],
"dceu": ["batman"],
"pixar": ["turning red"]
}
}
// Approach B
{
"movies/mcu": ["iron man", "the incredible hulk", "iron man 2", "thor", "captain america", "the avengers"],
"movies/dceu": ["batman"],
"movies/pixar": ["turning red"]
}
Both of these represent the same data, except instead of storing all of this information in one place, we’re flattening this data out across multiple entries in our key-value store. In approach B, all I need to do is to index into the datastore at the string value I construct (e.g. in this case, "movies/pixar"), and I can retrieve all of the movies that are affiliated with Pixar without having to retrieve a bunch of other data that was previously stored at the same location!
If efficiency is measured in read/write bandwidth (like it is in this project), then it’s much more efficient to represent our data in this flattened structure.
Minimizing Complexity
If you don’t need to store a certain piece of data, then don’t store it. Just recompute it (or re-fetch it, if it’s coming from datastore) “on-the-fly” when you need it. It’ll make your life easier!
Authenticated Encryption
In order to build in support for authenticated encryption, you may find it helpful to create a struct with two properties: (a) some arbitrary ciphertext, and (b) some tag (e.g. MAC, signature) over the ciphertext. Then, you could marshal that struct into a sequence of bytes, and store that in datastore. When loading it from datastore, you could (a) unmarshal it and check the tag for authenticity/integrity, and then decrypt the ciphertext and pass the plaintext downstream.
Checking for Errors
Throughout each API method, you’ll probably have several dozen error checks. Take a look at the following code for an example of good and bad practice when it comes to handling errors.
// This is bad practice: the error is discarded!
value, _ = SomeAPICall(...)
// This is good practice: the error is checked!
value, err = SomeAPICall(...)
if (err != nil) {
return err;
}
When an error is detected (e.g. malicious tampering occurred), your client just needs to immediately return. We don’t care about what happens afterwards (e.g. program state could be messed up, could have file inconsistency, etc. - none of this matters). In other words, we don’t care about recovery – we solely care about detection.
You should almost never discard the output of an error: always, always check to see if an error occurred!
Tips For Writing Test Cases
Here are a few different ways to think about creative tests:
- Functionality Tests
- Consider basic functionality for single + multiple users
- Consider different sequences of events of Client API methods
- Consider interleaving file sharing/revocation/loading/storing actions
- Edge Case Tests
- Consider edge cases outlined in the Design Overview and other parts of this specification.
- Security Tests
- Consider what happens when an attacker tampers with different pieces of data
In all cases, you should ensure that your Client API is following all requirements listed in the Design Overview.
Coverage Flags Tips
It’s okay if your tests don’t get all 20 test coverage points! Some flags are very tricky to get, and we don’t expect everyone to get all the flags. If you’re missing a few flags, a few points won’t make or break your project. That said, higher test coverage does mean you’re testing more edge cases, which means you can also be more confident in your own implementation if it’s passing all your tests.
Writing Advanced Tests
- Some students have reported success with fuzz testing, which uses lots of different random tampering attacks. Sometimes this can help you catch an edge case you weren’t expecting.
- Remember that your tests must work on any project implementation, not just your own implementation. This means you cannot assume anything about the design except the API calls that everyone implements (InitUser, GetUser, LoadFile, StoreFile, etc). For example, you cannot reference a field in a user struct in your tests, because other implementations might not have that field in their user struct.
- The userlib has a nifty DatastoreGetMap function which returns the underlying go map structure of the Datastore. This can be used to modify the Datastore directly to simulate attacker action.
DatastoreGetMapcan also be used to learn about how the Datastore is changed as a result of an API call. For example, you can scan the Datastore, perform an API call (e.g. StoreFile), then scan the Datastore again to see what has been updated. This can help you write more sophisticated tests that leverage information about what encrypted Datastore entries correspond to what data.
Writing Efficiency Tests
Here’s a helper function you can use to measure efficiency.
// Helper function to measure bandwidth of a particular operation
measureBandwidth := func(probe func()) (bandwidth int) {
before := userlib.DatastoreGetBandwidth()
probe()
after := userlib.DatastoreGetBandwidth()
return after - before
}
// Example usage
bw = measureBandwidth(func() {
alice.StoreFile(...)
})
Expect(err).ToNot(BeNil())
You should check for errors after every Client API call. This makes sure errors are caught as soon as they happen, instead of them propagating downstream. Don’t make any assumptions over which methods will throw and which errors won’t: use an Expect after each API method.
Remember the core principle around testing: the more lines of the staff solution you hit, the more flags you’re likely to acquire! Think about all of the if err != nil cases that may be present in the staff code, and see if you’re able to write tests to enter those cases.
value, err = user.InitUser(...);
Expect(err).ToNot(BeNil());
Suggested Design Workflow
This project has a lot of moving parts, and it’s normal to feel overwhelmed by the amount of requirements you need to satisfy in your design. Here is one suggestion for how you can break down this project into more manageable steps:
- Read through the entire spec. It’s easy to miss a design requirement, which might cause you trouble later when you have to redo your design to meet the requirement you missed. We suggest reading through the entire spec front-to-back at least twice, just to make sure that you have internalized all the design requirements.
- Design each section in order. Start with user authentication: How do you ensure that users can log in? Focus on getting
InitUserandGetUserproperly designed, and don’t worry about file storage or sharing yet. Then, after you’re satisfied with your login functionality, move on to the file storage functions. Don’t worry about sharing yet, and just make sure that a single user is able toLoadFileandStoreFileproperly. Then, you can move on toAppendToFile. Finally, once you’re satisfied with your single-user storage design, you can move on to sharing and revoking. - Don’t be afraid to redesign. It’s normal to change your design as you go. In particular, if you follow the order of functions in the spec, then
AppendToFilemight result in changes toLoadFileandStoreFile. Also,RevokeAccessmight result in changes toCreateInvitationandAcceptInvitation. It’s easier to change your design while you’re in the design phase; by contrast, it’s harder to change your design after you’ve already implemented it in code.
Suggested Coding Workflow
- Stay organized with helper functions. If you fit all your code in 8 functions, it’s easy for the functions to get bloated and hard to debug. By contrast, if you organize your code into helper functions, you can reuse code without needing to copy-paste code blocks, and you can also write unit tests to check that each helper function is working as intended.
- Test as you go. Don’t write a huge chunk of code and then test it at the end. This usually results in a failed test, and now you have no idea which part of the giant code block is broken. Instead, write small pieces of code incrementally, and write tests as you go to check that your code is doing what it’s supposed to.
- Don’t split the coding between partners. Sometimes, a 2-person project group will try to have each group member independently write half of the functions. As a design-oriented project, the code in different functions will often be connected in subtle ways, and it is difficult (if not impossible) to write code without understanding all the code that has been written so far. A better approach is to work together to figure out the high-level organization of your code. Ideally, you’d use a technique like pair programming to ensure that both partners understand the code being written. The only scenario where writing code individually might be useful is for isolated helper functions, where the behavior is clearly documented and the function can be tested and debugged in isolation. Staff are not responsible for helping you understand code that your partner wrote.
Suggested Development Environment
Visual Studio Code (VSCode)
VSCode is a very commonly used IDE, and provides a powerful set of code and debugging environments that can be exploited for Golang Projects. To setup VSCode for this project, follow these steps:
- Install Golang. Make sure you have Golang installed before starting this guide.
- Install the GoLang extension. In the “Extensions” tab (Use Ctrl+Shift+X to navigate you can’t find it), search up the Go extension that is created by Google.
- Install the debugging environment Once the extension is installed, the lower right corner might and most likely will pop up a warning stating that analysis tools might be missing. If so, click on the install, and wait for the analysis tools to install. If you missed this the first time, press (Ctrl+Shift+P) and search up “Extensions: Install Missing Dependencies,” and follow the instructions.
Debugging in VSCode
Once the extensions are installed we can now follow the debugging flow:
- Set breakpoints. To set a breakpoint in your code, Navigate to the line where you want your breakpoint to be, and click on the left side of the line number. You should see a red dot appearing next to the line number, which indicates that a breakpoint has been set.

- Run a test. To debug a test case and peek around the breakpoint, navigate to the
client_test/client_test.gofile, and click on thedebug testbutton above the test case that you want to run. Immediately after, the debugger will start. If your debugger doesn’t pause at breakpoints you’ve set, this means that your code flow never went through any lines of code that you’ve set a breakpoint on.
- Navigate the debugger. The golang debugger has a really convenient and powerful interface. There are a couple sections you should especially be aware of:
- You can step through your code using the menu bar at the center top of the screen just above the code editor (outlined in blue in the image below). Hover your mouse over each function to see the keyboard shortcut for each of these. This is a very important feature, so get familiar with each and every button.
- You can use the
local variablesat the top left quadrant of your screen (dash outlined in red in the image below), which displays the variable name and their values. For nested structures, you can click the expand button to view variables inside the struct. - You can use the
watchsection at the middle left quandrant of your screen (circled in green in the image below) to constantly evaluate golang expressions. Some of the thing you can use it for is to constant check the length of an array, which you can do withcall len([variable]). To constantly evaluate functions, you need to append the function call withcallfor watchpoints. - You can check the call stack in the
call stacksection, and edit breakpoints in thebreakpointssection.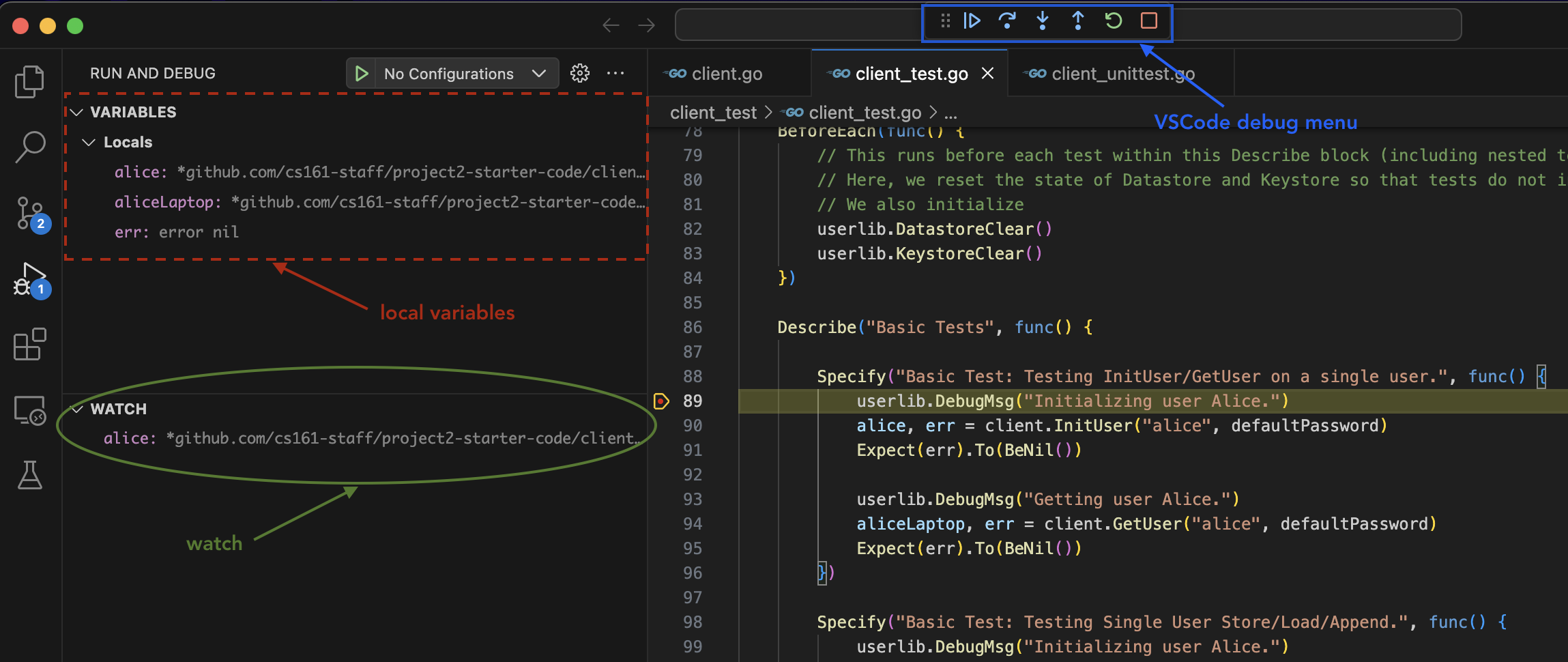
Notes on Key Reuse
In general, avoid reusing a key for multiple purposes. Why? Here’s a snippet from a post that former CS 161 Professor David Wagner wrote:
Suppose I use a key
kto encrypt and MAC a username (say), and elsewhere in the code I use the same keykto encrypt and MAC a filename. This might open up some attacks. For instance, an attacker might be able to take the encrypted username and copy-paste it over the encrypted filename. When the client decrypts the filename, everything decrypts fine, and the MAC is valid (so no error is detected), but now the filename has been replaced with a username.I’ve seen many protocols that have had subtle flaws like this.
There are two ways to protect yourself from this. One way is to think really, really hard about these kind of copy-paste attacks whenever you reuse a key for multiple purposes. The other way is to never reuse a key for multiple purposes. I don’t like to think hard. If I have to think hard, I often make mistakes. Or, as Brian Kernighan once wrote: “Everyone knows that debugging is twice as hard as writing a program in the first place. So if you’re as clever as you can be when you write it, how will you ever debug it?” So, I recommend way #2: never reuse a key for multiple purposes.
Hopefully this rationale will help you recognize the motivation behind that advice, which might help you recognize when the advice does or doesn’t apply.
Notes on Key Management
In order to simplify your key management scheme, it may be useful to store a small number of root keys, and re-derive many keys for specific purposes “on-the-fly” (a.k.a. when you need them) using the HashKDF function.
More Notes on Key Reuse
The term “key reuse” can be ambiguous.
As defined in our lecture, “key reuse” refers to the practice of using the same key in multiple algorithms. For example, if you use the same key to encrypt some data and HMAC that same data, this is a case of “key reuse” as defined in lecture. As discussed in lecture, you should always use one key per algorithm.
Note that using the same key to encrypt different pieces of data, or using the same key to MAC/sign different pieces of data, is not considered key reuse (as defined in lecture). Recall that the whole point of discarding one-time pads and introducing block ciphers was to allow for using the same key to encrypt different pieces of data.
Even though using one key per algorithm solves the “key reuse” problem from lecture, it doesn’t necessarily mean that other issues with key reuse don’t exist.
As an example, suppose you use the same, hard-coded key to encrypt every single value in your design. You use a different key (also hard-coded) to MAC every single value in your design. This is not a case of “key reuse” from lecture, because you did use one key per algorithm. However, this is still an insecure design because an attacker could read the hard-coded keys in your code and decrypt and modify all your stored data.
In summary: Reusing the same key in different algorithms is the “key reuse” problem from lecture, and you should always avoid this. Other cases of key reuse may exist in your design; it’s your job to figure out when these cases are problematic.
Strings and Byte Arrays
Be very careful about casting byte arrays to strings. Byte arrays can contain any byte between 0 and 255, including some bytes that correspond to unprintable characters. If you cast a byte array containing unprintable characters to a string, the resulting string could have unexpected behavior. A safer way to convert byte arrays to strings (and back) is to use the encoding/hex library, which we’ve imported for you.
If you instead need to convert strings to byte arrays (and back), you can use json.Marshal. Recall that marshalling works on any data structure, including strings.